The Ultimate Guide to Industrial Data Fabric: Revolutionizing Maintenance in 2025
Jul 21, 2025
industrial data fabric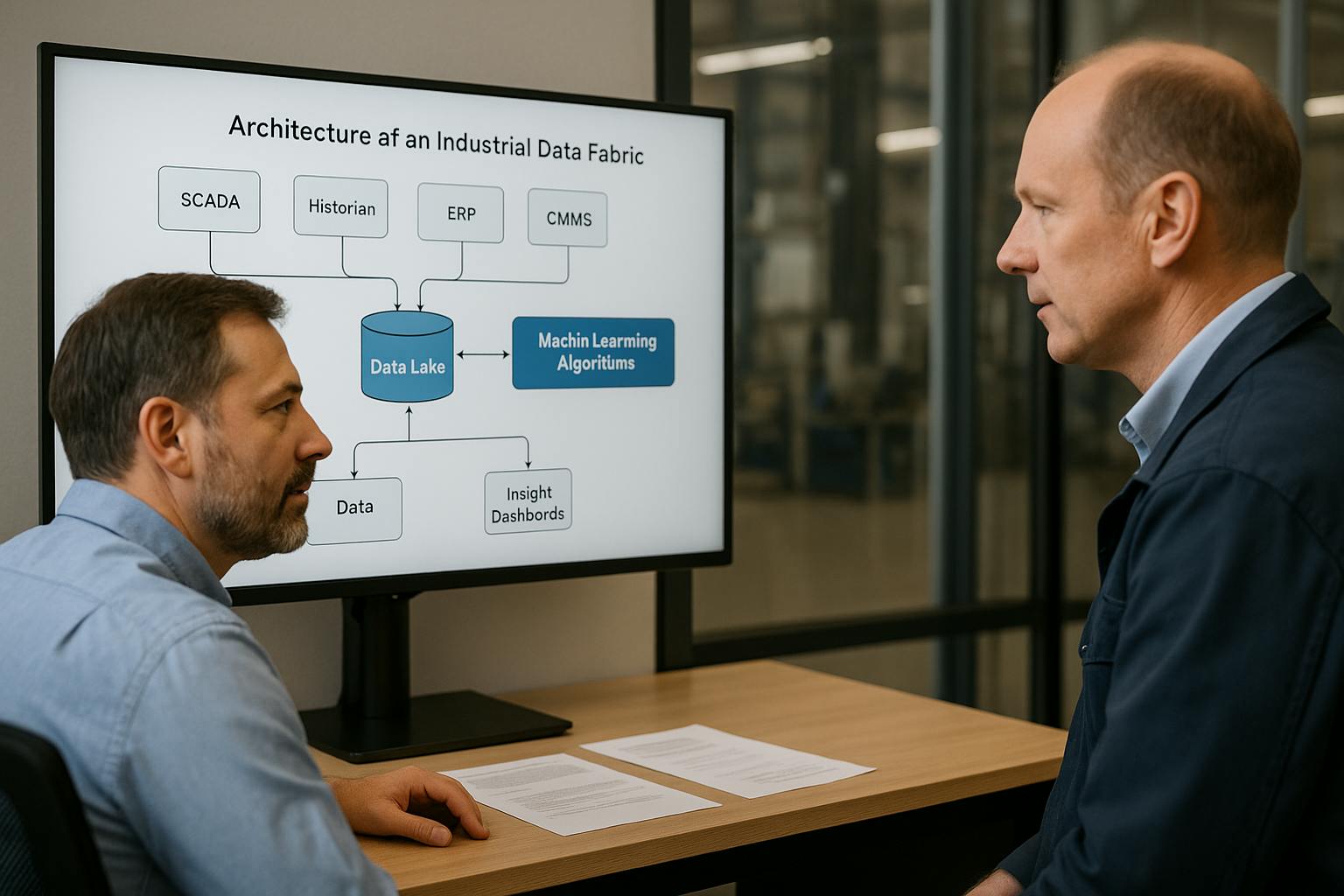
The morning meeting starts the same way it always does. A critical asset—let's say a primary compressor on Line 3—went down overnight. The production manager is staring at you, the maintenance manager, wanting answers. Your SCADA system shows a pressure drop and a spike in motor temperature right before the failure, but the alerts were buried in a sea of non-critical notifications. Your CMMS has the asset's full maintenance history, but it’s a manual process to correlate that with the real-time sensor data. The spare motor is in inventory, according to the ERP, but is it the exact right model? And was this failure preventable?
This daily fire-drill, a frantic scramble to connect disparate pieces of information, is the reality in countless manufacturing plants and industrial facilities. You have more data than ever before, yet true insight feels further away. The problem isn't a lack of data; it's that your data is trapped in silos, speaking different languages, and unable to communicate.
Enter the industrial data fabric.
As we navigate 2025, this is no longer a futuristic buzzword. It's a foundational architecture that is fundamentally changing how maintenance and operations teams work. It's the solution to the data chaos, the enabler of true proactive maintenance, and the engine for operational excellence. This comprehensive guide is written for you—the maintenance manager, the reliability engineer, the facility operator—to demystify the industrial data fabric and provide a practical roadmap for leveraging its power to transform your maintenance strategy.
What is an Industrial Data Fabric (and What It's Not)?
Before we dive into the "how," we need to establish a clear, practical understanding of the "what." The term "data fabric" can feel abstract, but at its core, it's a simple concept with profound implications for the factory floor.
Beyond the Buzzword: A Practical Definition for Maintenance Teams
Imagine your facility's data is like water. Historically, you've built separate plumbing systems for every need. The OT (Operational Technology) systems like PLCs and SCADA have their own pipes. The IT (Information Technology) systems like your CMMS and ERP have theirs. To get water from one system to another, you have to run a custom pipe each time, and it's a slow, brittle, and expensive process.
An industrial data fabric is like upgrading to a modern, unified city water grid. It's an intelligent, distributed data management architecture that creates a network connecting all your data sources—no matter where they are or what format they're in. It doesn't require you to move all your data into one giant central tank (like a traditional data warehouse). Instead, it allows any authorized application or user to access data on-demand, in a clean, contextualized, and ready-to-use format.
For a maintenance manager, this means you can finally get a single, unified view of your assets. You can see real-time sensor data from your SCADA system alongside the maintenance history from your CMMS software and the spare parts information from your ERP, all in one place, all in real-time.
Key Characteristics of a True Industrial Data Fabric
Not every solution that claims to integrate data is a true data fabric. Here are the defining characteristics you should understand:
- Distributed Architecture: The fabric accesses data where it lives. It minimizes data replication and movement, which is crucial for handling the massive volumes of high-velocity data from the plant floor.
- Data Virtualization & Integration: This is the core of its connectivity. It uses a powerful layer of connectors and APIs to talk to everything from decades-old PLCs using Modbus to modern cloud applications. It abstracts away the complexity of the underlying sources.
- Active Metadata & Semantics: This is the "magic." A data fabric doesn't just move data; it understands it. It uses a semantic layer to enrich raw data with context.
Tag_54321becomesLine3_Compressor_Motor_Vibration_X-Axis. This process, known as data contextualization, is what turns raw numbers into actionable information. - Built-in Governance and Security: It provides a centralized way to manage data access, quality, and security policies across all connected systems, which is critical for bridging the IT/OT gap.
- DataOps-Enabled: A modern data fabric supports Industrial DataOps, an agile methodology for automating the design, deployment, and management of data pipelines. This allows you to rapidly build and adapt new analytics use cases without massive, months-long projects.
Industrial Data Fabric vs. Traditional Data Integration Methods
To appreciate the fabric's innovation, it's helpful to compare it to older methods:
| Method | Description | Drawbacks for Maintenance |
|---|---|---|
| Point-to-Point Integrations | Custom code is written to connect System A to System B. Another custom code connects A to C. | Creates a brittle "spaghetti architecture." It's expensive to build, impossible to maintain, and doesn't scale. Adding a new system requires new custom code for every connection. |
| Data Warehouse / Data Lake | All data is copied (ETL - Extract, Transform, Load) into a massive, centralized repository. | Data is often stale by the time it's loaded. It's not designed for real-time operational decisions. It loses the context of the source system and requires immense effort to clean and prepare for analysis. |
| Industrial Data Fabric | Connects to systems virtually, leaving data in place. Contextualizes and serves data on demand. | Provides a single source of truth without mass data duplication. Enables real-time access and agility. Scales easily as new sources or applications are added. |
The Core Problem: Why Your Plant Floor Data is Trapped in Silos
The need for a data fabric arises from a decades-old problem that has only intensified with the rise of IIoT: the deep-seated division between different data-generating domains in an industrial environment.
The Great IT/OT Divide: A Lingering Challenge
The root of data silos lies in the historical and cultural separation of Information Technology (IT) and Operational Technology (OT).
- OT (Operational Technology): This is the world of the plant floor. It includes PLCs, SCADA systems, DCS, and historians. Its priorities are uptime, control, and determinism. It uses specialized industrial protocols (e.g., Modbus, Profinet, OPC-DA) and operates in highly secured, often air-gapped networks. The data is time-series, high-frequency, and cryptic to the uninitiated.
- IT (Information Technology): This is the world of the enterprise. It includes ERP, CMMS, and business intelligence systems. Its priorities are data integrity, transaction processing, and enterprise-wide reporting. It uses standard protocols like TCP/IP, HTTP, and SQL.
This divide creates a technical and organizational chasm. IT/OT convergence has been a goal for years, but it's incredibly difficult to achieve with traditional tools. The data fabric acts as the diplomatic bridge, speaking both languages and allowing for a secure, governed flow of information between these two worlds.
A Day in the Life of Disconnected Data
Let's revisit our failed compressor scenario to see the impact of these silos in painful detail:
- The Event: The compressor fails at 2:15 AM. The SCADA system logs hundreds of alarms, including the critical vibration and temperature spikes, but they are mixed with low-priority alerts.
- The Discovery: The night shift operator notices the line stoppage and reports it. A maintenance technician is dispatched.
- The Investigation (Manual Correlation):
- The technician pulls up the SCADA trend data on one screen.
- On another computer, they log into the CMMS to find the asset ID, check for recent work orders, and look up the maintenance manual PDF.
- They call the storeroom clerk to verify if the spare part listed in the CMMS is physically on the shelf.
- They might have to find the reliability engineer who has a separate analytics tool with historical vibration data stored in a data lake, but that data is only updated once a day.
- The Result: Hours are wasted connecting dots that a machine could connect in milliseconds. The true root cause might be missed, leading to a repeat failure. Production losses mount with every passing minute.
The High Cost of Data Silos in Maintenance
This single scenario, multiplied across all assets and all potential failure modes, highlights the staggering cost of disconnected data:
- Increased Mean Time to Repair (MTTR): Technicians spend more time diagnosing than fixing.
- Dominance of Reactive Maintenance: It's impossible to be proactive when you can't see the full picture of asset health in real-time.
- Inefficient Resource Allocation: Technicians are dispatched based on alarms, not on predictive insights. MRO inventory is managed based on historical averages, not on forward-looking failure predictions.
- Inability to Perform Advanced Analytics: Your data scientists and reliability engineers spend 80% of their time just trying to find, clean, and merge data instead of building models that could prevent failures.
- Safety Risks: A lack of holistic asset visibility can lead to equipment being operated in unsafe conditions.
How an Industrial Data Fabric Unlocks Proactive Maintenance
A data fabric isn't just about connecting systems; it's about enabling entirely new capabilities that shift the maintenance paradigm from reactive to predictive and, ultimately, prescriptive.
The Power of Data Contextualization: From Raw Numbers to Actionable Insights
This is the most critical function of an industrial data fabric for maintenance teams. Data contextualization is the process of adding layers of meaning to raw data points to make them understandable and useful.
A sensor on a PLC might output a value like N7:10 = 450. By itself, this is meaningless. The data fabric enriches this data through its semantic model:
- What is it? It connects to the PLC's tag database to know
N7:10isMotor_Current. - Where is it? It connects to the asset hierarchy (often from the CMMS or an engineering drawing) to know this motor is part of
Line3_Compressor_A. - What are its properties? It adds engineering units (
Amps), the motor's model number, its installation date, and its nameplate full-load amperage. - What is its state? It compares the real-time value to operational limits and historical trends to determine if
450 AmpsisNormal,Warning, orCritical.
The final, contextualized data point looks like this: { "asset": "Line3_Compressor_A", "point": "Motor_Current", "value": 450, "units": "Amps", "status": "Critical", "limit": 425 }.
A popular and powerful way to implement this contextualization is through a Unified Namespace (UNS). A UNS is an event-driven, centralized information hub for your entire organization. It organizes all data points into a single, logical, hierarchical structure (e.g., Enterprise/Site/Area/Line/Asset/Signal). The data fabric is the architecture that populates and serves data from this UNS, ensuring every piece of data has a consistent, understandable address and context.
Fueling Predictive Maintenance Analytics
Predictive maintenance (PdM) promises to fix assets right before they fail. However, the biggest barrier to successful PdM has always been data. AI and Machine Learning models are hungry for vast amounts of clean, contextualized, and correlated data.
This is where the data fabric becomes a game-changer. It acts as the perfect data delivery service for your analytics platform.
- Eliminates Data Wrangling: It automates the painful process of data preparation. Instead of spending months cleaning and merging data from different silos, your data science team gets a continuous, analysis-ready stream of contextualized data.
- Enables Feature Engineering: By unifying OT and IT data, it allows models to use more powerful predictive features. For example, a model predicting a motor failure can now use not only real-time vibration and temperature but also the time since the last maintenance, the manufacturer of the installed bearings, and even the ambient weather conditions.
- Powers Real-Time Inference: Once a model is trained, the data fabric can feed it live, contextualized data, allowing for real-time predictions that can trigger immediate alerts.
With a data fabric in place, implementing sophisticated AI predictive maintenance becomes dramatically simpler and faster. You can finally build effective models for your most critical assets, from pumps and compressors to complex robotic systems. For instance, you could create a specific model for predictive maintenance on motors by feeding it contextualized current, temperature, and vibration data, correlated with work order history for that specific asset class.
Supercharging Your CMMS with Real-Time Data
Your CMMS is the system of record for maintenance, but it's often a passive, historical database. An industrial data fabric turns it into a dynamic, living system. This deep CMMS data integration creates a powerful bi-directional loop:
- From OT to CMMS: The data fabric's analytics layer detects an anomaly—say, a bearing vibration signature that indicates impending failure.
- Automated Work Order Generation: It automatically triggers the creation of a work order in the CMMS.
- Context-Rich Work Orders: This isn't a blank work order. It's pre-populated with the Asset ID, the specific fault code ("Predicted Bearing Failure - Stage 2"), the real-time sensor readings that triggered the alert, a link to the historical data trend, and even a list of required spare parts and standard repair procedures.
- From CMMS to OT: When the work order is completed, that information is fed back through the data fabric into the asset's digital history. The analytics models now know that maintenance was performed, which is critical for retraining and improving the model's accuracy.
Enabling the True Digital Twin for Manufacturing
The digital twin is a virtual representation of a physical asset or process. A static 3D model is not a digital twin. A true, living digital twin is continuously updated with real-time data from its physical counterpart.
The industrial data fabric is the central nervous system that makes the digital twin possible.
- It feeds the twin with a constant stream of high-fidelity, contextualized data from every relevant source (OT and IT).
- It allows you to simulate "what-if" scenarios on the twin (e.g., "What happens if we increase the line speed by 10%?") and see the predicted impact on asset health and performance.
- It can push insights back to the physical world. For example, an optimization calculated in the digital twin could be sent back through the data fabric to adjust a setpoint on a PLC.
Without a data fabric, building and maintaining a true digital twin is a monumental, if not impossible, integration challenge.
A Practical Guide: Implementing an Industrial Data Fabric in Your Facility
Adopting a data fabric is a journey, not a single project. The key is to start small, prove value, and scale incrementally. Here is a step-by-step approach designed for maintenance and operations teams.
Step 1: Assembling Your Cross-Functional Team
This cannot be an IT-only or an OT-only project. Success is built on collaboration. Your core team should include:
- Maintenance & Reliability: You are the "customer." You define the problems to be solved and the use cases (e.g., "We need to predict failures on our main extruders").
- OT/Controls Engineering: They understand the plant floor systems, the PLCs, the networks, and the industrial protocols. They are the keepers of the source OT data.
- IT Department: They manage the enterprise systems (CMMS, ERP), the core network infrastructure, and cybersecurity policies.
- Executive Sponsor: A leader with budget authority who understands the strategic value and can champion the project across departments.
Step 2: Start Small - The "Slice of the Plant" Approach
Don't try to connect everything at once. This "boil the ocean" approach is a recipe for failure. Instead, pick a single, high-impact pilot project.
- Identify a Critical Pain Point: Choose an asset or process that is a well-known source of downtime, quality issues, or high maintenance costs. A bottleneck machine is a perfect candidate.
- Define a Clear, Measurable Goal: Be specific. For example: "Reduce unplanned downtime on the Line 5 packaging machine by 25% within 6 months by implementing condition monitoring for its main drive motor and gearbox."
Step 3: Mapping Your Data Sources and Consumers
For your pilot project, create a simple map.
- Data Sources: List every system that has relevant data. For the packager example, this could be:
- PLC (motor current, speed)
- Add-on vibration and temperature sensors (IIoT)
- CMMS (asset ID, maintenance history, failure codes)
- MES (production schedule, current product SKU)
- Data Consumers: Who or what will use this integrated data?
- A condition monitoring dashboard for the maintenance team.
- An alerting system that sends notifications to technicians.
- A reliability engineer's analytics tool.
Step 4: Choosing the Right Technology Stack (Vendor-Agnostic Principles)
While this guide is vendor-agnostic, there are key technical principles and components to look for when evaluating data fabric technologies:
- Broad Connectivity: Ensure it has off-the-shelf connectors for your specific OT protocols (OPC-UA, Modbus, Ethernet/IP, etc.) and IT systems (SQL, REST APIs). Support for open standards like MQTT and OPC-UA is non-negotiable as they are the lingua franca of modern industrial communication.
- Semantic Modeling Layer: The tool must have an intuitive way to build your asset hierarchy and apply context to raw data tags. This is the heart of the fabric.
- Data Virtualization Engine: Look for the ability to query data in place without being forced to move it all into a new database.
- Scalability and Edge Capability: The architecture should be able to run components at the edge (close to the machines) for low-latency processing and on-premise or in the cloud for enterprise-wide analytics.
Step 5: Building the First Data Pipeline and Proving Value
With your team, pilot project, and technology principles in place, execute the first implementation.
- Connect the data sources for your chosen asset.
- Build the semantic model for that asset, contextualizing its data points.
- Create a simple dashboard that displays the unified view of the asset's health.
- Set up alerts based on simple rules or thresholds.
- Track the results against your goal. Did you catch a developing issue before it caused a failure? Did MTTR decrease because technicians had all the information upfront?
- Calculate the ROI—even if it's a rough estimate—and present it to your executive sponsor to get buy-in for the next phase.
Step 6: Scaling Out - The Role of Industrial DataOps
Once you've proven the value with your pilot, it's time to scale. This is where Industrial DataOps becomes essential. As defined by experts at sources like Reliabilityweb, DataOps applies the principles of DevOps (automation, collaboration, continuous improvement) to your data pipelines. It's a methodology that helps you:
- Automate the deployment of new data connections and analytics.
- Monitor the health and quality of your data pipelines.
- Version control your semantic models and analytics code.
- Collaborate effectively between IT, OT, and maintenance teams.
Adopting a DataOps approach ensures that as you scale your data fabric from one asset to the entire plant, you can do so in an agile, reliable, and governed way.
Real-World Impact: Industrial Data Fabric Case Studies
Let's look at how this plays out in hypothetical but realistic scenarios.
Case Study 1: Automotive Manufacturer - Predictive Maintenance on a Robotic Welding Line
- Problem: Unpredictable failures in the servo motors of welding robots were a primary cause of line stoppages, costing over $20,000 per minute in lost production.
- Solution: They implemented an industrial data fabric to unify three key data sources: 1) Real-time motor current, torque, and position error from the robot controller. 2) Data from retrofitted IIoT vibration sensors. 3) Failure history and repair details from their CMMS.
- Result: The contextualized data stream was fed into a machine learning model. The model now predicts servo motor degradation with 95% accuracy, up to two weeks before failure. The fabric automatically generates a predictive work order in the CMMS, allowing maintenance to be scheduled during planned weekend shutdowns. Uptime on the welding line increased by 18%, and urgent parts shipments were virtually eliminated.
Case Study 2: Water Treatment Facility - Asset Performance Management (APM)
- Problem: A municipal water utility needed to manage hundreds of pumps and valves spread across a large geographic area with a lean maintenance team. Technicians were spending hours driving between sites on a time-based maintenance schedule, often inspecting perfectly healthy equipment.
- Solution: They built their Asset Performance Management (APM) strategy on a data fabric architecture. The fabric collected real-time pressure, flow, and power consumption data from remote sensors via a cellular IIoT network. It integrated this with GIS data for asset location and the asset hierarchy from their CMMS.
- Result: A centralized operations center now has a real-time health dashboard for every asset. Condition-based alerts are sent directly to the technician's mobile CMMS app, complete with the asset's location, real-time data, and maintenance history. This reduced truck rolls by 40%, increased wrench time by 30%, and allowed them to defer non-essential capital upgrades by demonstrating the health of existing assets.
Overcoming Common Hurdles and Best Practices for Success
The path to implementing a data fabric will have challenges. Being prepared for them is key.
Troubleshooting Common Implementation Challenges
- Challenge: Resistance to Change. Both IT and OT teams can be protective of their domains.
- Solution: Start with the "why." Get executive sponsorship to communicate the strategic importance. The pilot project is your best tool; by solving a real, painful problem for the maintenance and operations team, you create internal champions who will pull the project forward.
- Challenge: Legacy Equipment. What about the 30-year-old PLC that doesn't have an Ethernet port?
- Solution: This is a problem data fabrics are designed to solve. Use edge gateways and protocol converters to extract data from older serial or proprietary networks and publish it to the fabric using modern standards like MQTT. You don't need to rip and replace old equipment to get its data.
- Challenge: Data Security Concerns. IT is rightfully concerned about connecting plant floor systems to the enterprise network.
- Solution: A well-architected data fabric enhances security. It can utilize DMZs and one-way data flows out of the OT network. Because it can access data in place, it minimizes attack surfaces. Centralized governance means you have a single place to enforce security policies. Adhering to standards like the NIST Cybersecurity Framework is essential.
Best Practices for Long-Term Success
- Treat Data as a Strategic Asset: Shift the organizational mindset. Data is not an exhaust byproduct of operations; it is a valuable asset that can create a competitive advantage.
- Foster a Data-Driven Culture: Make dashboards and insights accessible to everyone, from the plant manager to the technician on the floor. When people see how data can make their jobs easier and more effective, they will embrace it.
- Start with the "Why," Not the "What": Don't implement technology for technology's sake. Always start with a clear business problem that needs solving.
- Govern from Day One: Establish clear ownership and standards for your data models (like the UNS) from the beginning. A well-governed fabric is a reliable fabric.
The Foundation for the Future of Maintenance
The days of hunting for information across a dozen different screens are numbered. The industrial data fabric is the architectural key that unlocks the full value of the data you already have. It breaks down the walls between IT and OT, transforms raw data into actionable wisdom, and provides the clean, contextualized, real-time fuel required for advanced maintenance strategies.
By moving beyond siloed systems to a unified data architecture, you empower your team to shift from a reactive, stressful firefighting mode to a proactive, data-driven, and strategic function. You lay the groundwork for powerful technologies like true AI-driven predictive maintenance, living digital twins, and prescriptive analytics that don't just tell you when an asset will fail, but recommend the optimal way to respond.
The journey to a fully connected, intelligent plant begins with a single, unified view of your data. By embracing an industrial data fabric, you’re not just adopting new technology; you’re building the foundation for the future of maintenance and operational excellence at your facility. It's time to connect your data and unlock your plant's true potential. Start the conversation today to see how you can begin your journey with a powerful predictive maintenance solution.
