Beyond the Hype: Your 2025 Guide to Implementing a Cloud-Based Predictive Maintenance Platform
Sep 13, 2025
cloud-based predictive maintenance platform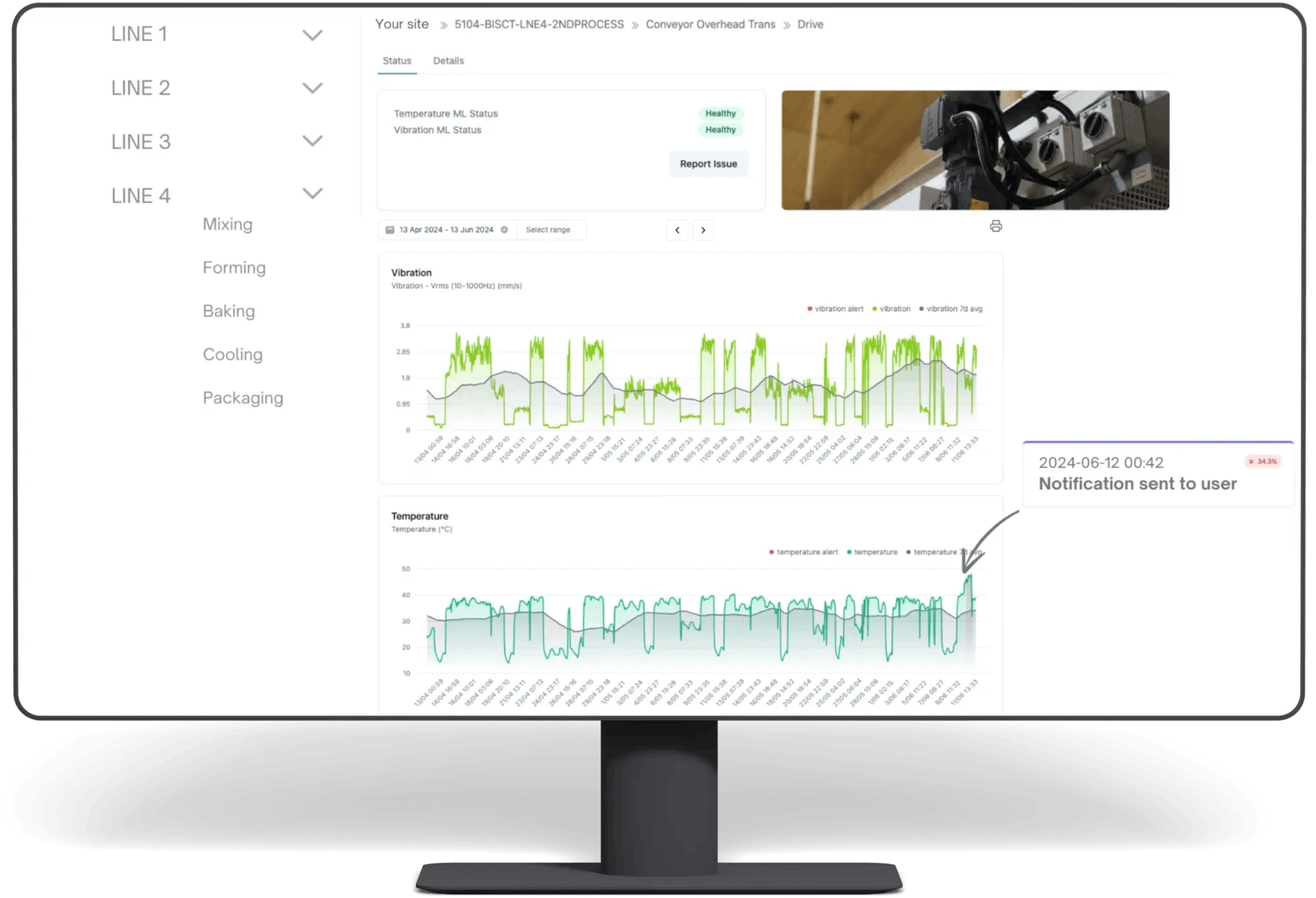
You’ve heard the promises: zero unplanned downtime, maintenance costs slashed by 40%, and production lines humming with near-perfect efficiency. The concept of predictive maintenance (PdM) has been touted as the cornerstone of Industry 4.0 for years. Yet for many maintenance managers and operations leaders, it remains an elusive, futuristic dream. The path from your current state—a constant battle of reactive firefighting and rigid preventive schedules—to a fully-realized predictive strategy seems shrouded in mystery, complexity, and prohibitive cost.
This is where the conversation shifts. In 2025, the question is no longer if you should adopt predictive maintenance, but how. The key that unlocks this capability for facilities of all sizes is the cloud-based predictive maintenance platform.
This is not another high-level article that simply defines the term. This is a comprehensive, in-depth guide for the pragmatists, the engineers, and the financial decision-makers. We will provide a practical implementation roadmap, a clear framework for justifying the investment, and a technical deep dive into the components that make these platforms work. It's time to stop dreaming and start doing.
Why "Cloud-Based" is the Game-Changer for Predictive Maintenance
While predictive maintenance as a concept isn't new, its widespread adoption was historically limited to capital-intensive industries like aerospace and energy, requiring massive on-premise servers, teams of data scientists, and bespoke software. The cloud changes everything. A cloud-based platform democratizes this powerful technology, making it accessible, scalable, and more intelligent than ever before.
Scalability on Demand
With traditional on-premise solutions, scaling up meant a significant capital expenditure project. You needed more servers, more software licenses, and more IT infrastructure to add a new production line or an entire facility. A cloud-based platform operates on a subscription-as-a-service (SaaS) model. This means you can start with a small pilot program on a handful of critical assets and scale seamlessly as you prove the value. Adding new assets, data streams, or entire sites doesn't require a hardware overhaul; it's a simple adjustment to your subscription, allowing your technology to grow with your success.
Centralized Intelligence & Accessibility
Imagine managing multiple facilities across the country or even the globe. With an on-premise system, data is often siloed at each location. A cloud platform acts as a single source of truth, centralizing asset health data from every corner of your operation into one unified dashboard. A maintenance manager in Texas can diagnose an emerging issue on a machine in Germany, collaborate with the local team, and track the resolution in real-time. This level of visibility is further enhanced by platforms that offer a full-featured mobile CMMS, putting critical asset data and work order management directly into the hands of technicians on the plant floor.
The Power of Pooled Data & Advanced AI
This is perhaps the most significant, yet often overlooked, advantage of the cloud. A vendor's platform learns not just from your machines, but from the anonymized data of thousands of similar assets across its entire customer base. This vast, diverse dataset allows them to build incredibly robust and accurate AI models for specific asset classes (e.g., a 500hp centrifugal pump from a particular manufacturer). Your organization benefits from this collective intelligence from day one, achieving faster and more accurate predictions than you ever could with only your own historical data.
Lower Total Cost of Ownership (TCO)
The financial barrier to entry for PdM has crumbled thanks to the cloud. Instead of a massive upfront investment in hardware, software development, and specialized IT personnel, you pay a predictable monthly or annual subscription fee. The vendor handles all the backend infrastructure, including server maintenance, security, software updates, and the continuous development of their AI models. This shifts the cost from a capital expense (CapEx) to a more manageable operating expense (OpEx), dramatically lowering the TCO and accelerating the time to ROI.
The Pragmatist's Roadmap: A Phased Approach to PdM Implementation
The single biggest mistake companies make is attempting a "big bang" implementation. Trying to connect every asset and overhaul every process at once is a recipe for budget overruns, frustrated teams, and ultimate failure. The key to success is a phased, "crawl-walk-run" strategy that builds momentum, demonstrates value, and fosters organizational buy-in.
Phase 1: The Foundation (Crawl - Months 1-3)
This phase is about laying the groundwork and achieving a quick, tangible win.
Step 1: Asset Criticality Analysis You cannot and should not monitor everything. The first step is to identify which assets matter most. A standard method is the Asset Criticality Analysis, which plots assets on a matrix based on two factors:
- Consequence of Failure (CoF): What happens if this asset fails? Consider impacts on production, safety, environmental compliance, and repair cost.
- Probability of Failure (PoF): How likely is this asset to fail? Use historical data from your CMMS, technician knowledge, and manufacturer recommendations.
Assets in the high-consequence, high-probability quadrant are your prime candidates for the pilot program. You can find excellent templates and guides for this process from sources like Reliabilityweb.
Step 2: Select Your Pilot Program Choose 5-10 of your most critical and problematic assets identified in the analysis. Don't pick the easiest asset; pick one whose failure causes real pain. This ensures your pilot's success will be meaningful. Good candidates often include:
- Process-critical pumps
- Main conveyor drive motors
- Reciprocating compressors
- Gearboxes on production lines
Focusing on a specific asset class can be highly effective. For example, you could build a pilot around your most vital pumps, leveraging a specialized solution like a predictive maintenance platform for pumps to gain deep insights.
Step 3: Establish a Data Baseline What data do you already have? This is where you connect your existing systems. The most valuable initial source is your historical maintenance records. A modern PdM platform can ingest years of data from your CMMS software, analyzing past work orders, failure codes, and technician notes to begin understanding failure patterns even before a single sensor is installed. You also need to document the asset's nameplate data, operational context, and any existing process data (e.g., from a SCADA system).
Step 4: Basic Condition Monitoring Start simple. You don't need a complex array of sensors for your pilot. For most rotating equipment, a combination of wireless vibration and temperature sensors is a cost-effective and powerful starting point. The goal in this phase is to begin collecting real-time data and establishing a normal operating baseline for each pilot asset.
Phase 2: Building Intelligence (Walk - Months 4-12)
With the foundation in place, this phase is about leveraging the platform to turn data into actionable intelligence.
Step 1: Deploying the Cloud Platform This is where you onboard your pilot assets into the cloud-based PdM platform. You'll work with the vendor to configure asset hierarchies, set up user profiles, and build initial dashboards. A good vendor will provide significant support during this phase to ensure a smooth onboarding process.
Step 2: Integrating Data Streams Now, you connect the dots. The sensor data from your pilot assets is streamed to the cloud platform. Crucially, you must ensure the platform has robust integrations to connect seamlessly with your CMMS/EAM. This creates a closed loop: the PdM platform detects a potential failure, and the CMMS manages the execution of the corrective work.
Step 3: From Condition Monitoring to Predictive Alerts During this period, the platform's machine learning models are in a "learning mode." They analyze the streaming sensor data to understand the unique signature of each asset's healthy operation. After a few weeks or months, the system can move beyond simple condition-based alerts (e.g., "Vibration is high") to true predictive alerts (e.g., "Vibration patterns indicate a 90% probability of a bearing failure in the next 15-30 days").
Step 4: Refining Workflows An alert is useless if it doesn't trigger action. Configure the platform to automatically generate a work order draft in your work order software when a predictive alert is issued. This draft should include the asset ID, the predicted failure mode, the supporting data (vibration/temp graphs), and a recommended timeframe for action. This automates the administrative burden and ensures nothing falls through the cracks.
Phase 3: Scaling & Optimizing (Run - Months 13+)
With a successful pilot, proven ROI, and refined workflows, you're ready to expand and deepen the program's impact.
Step 1: Expanding the Program Use the data, case studies, and ROI calculations from your pilot to build a business case for a facility-wide or enterprise-wide rollout. Systematically work your way down your asset criticality list, onboarding new assets and lines onto the platform.
Step 2: Introducing Prescriptive Maintenance This is the next evolution. The most advanced platforms don't just predict a failure; they prescribe the solution. By correlating sensor data with specific failure codes and repair actions from your CMMS, the system can provide recommendations like: "Failure predicted in Motor 3B. Root cause: bearing cage fault. Recommended action: Replace bearing with part #XYZ-123. See attached procedure." This level of guidance, known as prescriptive maintenance, dramatically reduces troubleshooting time and ensures the correct repair is performed the first time.
Step 3: The Digital Twin Era The data collected and structured within your cloud platform becomes the foundation for a dynamic digital twin. This isn't just a 3D model; it's a living, virtual representation of your physical asset, updated in real-time with sensor data. This allows you to run simulations, test the impact of different operational parameters (e.g., "What happens to the asset's RUL if we increase the line speed by 10%?"), and optimize performance in a virtual environment before implementing changes in the real world. For more on this, you can explore resources from institutions like NIST on Digital Twin technology.
Step 4: Continuous Improvement The PdM platform becomes a powerful tool for your reliability engineering team. Use its analytics to identify bad actors (assets that fail frequently), optimize your MRO inventory based on predictive needs, and refine your preventive maintenance tasks. For example, you might discover that a monthly PM task is unnecessary and can be shifted to a semi-annual schedule based on the asset's actual condition, freeing up valuable technician time.
The CFO's Briefing: Justifying the Investment in a PdM Platform
To get executive buy-in, you must speak their language: money. A cloud-based PdM platform is not a cost center; it's a profit-driving investment. Here’s how to frame the conversation and build an undeniable business case.
Deconstructing the ROI Calculation
The Return on Investment (ROI) is the cornerstone of your proposal. It's calculated as (Net Gain from Action / Cost of Action) x 100. Let's break down the components.
The "Cost of Inaction" (The Value of the Problems You're Solving) This is the financial pain your organization currently endures.
- Cost of Unplanned Downtime: This is your biggest lever. The formula is:
(Lost Production Rate per Hour x Hours of Downtime) + (Labor Costs for Repair x Hours of Downtime) + Restart Costs.- Example: A critical packaging machine produces $10,000 worth of product per hour. A typical bearing failure causes 4 hours of unplanned downtime. The cost is
($10,000 x 4) = $40,000in lost production alone, not including labor or secondary damage. If this happens 5 times a year, that's $200,000 from a single failure mode on one asset.
- Example: A critical packaging machine produces $10,000 worth of product per hour. A typical bearing failure causes 4 hours of unplanned downtime. The cost is
- Cost of Reactive Maintenance: Industry studies consistently show that reactive maintenance is 3 to 5 times more expensive than planned maintenance due to overtime labor, expedited shipping for parts, and the higher likelihood of secondary damage to other components.
- Excess MRO Inventory Costs: In a reactive world, you stock "just-in-case" inventory. This ties up capital and incurs carrying costs (typically 15-25% of the inventory's value per year). A robust inventory management system linked to PdM allows for a leaner, "just-in-time" approach.
- Safety & Environmental Costs: Catastrophic failures can lead to safety incidents, which carry immense direct and indirect costs (fines, insurance premium hikes, legal fees, reputational damage).
The "Gains from Action" (The Benefits of the Platform)
- Increased Production (OEE Improvement): The primary goal is to convert unplanned downtime into planned uptime. A 5-10% reduction in unplanned downtime can translate directly to millions in additional revenue-generating production.
- Reduced Maintenance Costs: By shifting from reactive to planned work, you can reduce overtime, eliminate rush freight charges, and perform maintenance more efficiently. A typical reduction is in the 20-30% range.
- Extended Asset Lifespan: PdM is like preventative healthcare for your machines. By catching problems early, you prevent small issues from cascading into catastrophic failures, thereby extending the useful life of multi-million dollar assets.
- Optimized Energy Consumption: Unhealthy assets often consume more energy. A misaligned motor or a pump with a clogged filter works harder and draws more power. The platform can help identify these inefficiencies.
Building Your Business Case: A Template
- Executive Summary: A one-page overview of the problem, solution, and expected financial impact (e.g., "We propose a $100k investment in a cloud PdM platform to address $500k in annual downtime costs, with an expected payback period of 8 months and a 3-year ROI of 400%").
- Problem Statement: Detail the current state using hard numbers. "In 2024, we experienced 850 hours of unplanned downtime, costing an estimated $2.5M in lost production. Our maintenance costs were 15% over budget due to reactive work."
- Proposed Solution: Describe the cloud-based PdM platform and the phased implementation plan.
- Financial Analysis: Show your work. Detail the ROI calculation, Payback Period, and Net Present Value (NPV). Use the numbers from your pilot program to make the projections credible.
- Risks & Mitigation: Address potential challenges (e.g., employee adoption, data quality) and how you plan to mitigate them.
The Engineer's Deep Dive: Under the Hood of a Modern PdM Platform
For the technical stakeholders, understanding the "how" is just as important as the "why." A true cloud-based PdM platform is a sophisticated ecosystem of hardware, software, and data science.
The Data Acquisition Layer: Sensors and Connectivity
This is where the physical world meets the digital. The quality of your data acquisition strategy directly impacts the quality of your predictions.
- Common Sensor Types:
- Vibration Analysis: The workhorse of PdM for rotating equipment. Tri-axial accelerometers measure vibration in different planes to detect issues like imbalance, misalignment, bearing faults, and gear mesh problems.
- Temperature: Infrared sensors and Resistance Temperature Detectors (RTDs) can spot overheating in motors, bearings, and electrical panels, often an early sign of friction or electrical issues.
- Acoustic Analysis: Ultrasonic sensors "hear" high-frequency sounds imperceptible to the human ear, which are excellent for detecting early-stage bearing faults, lubrication issues, and gas/air leaks.
- Motor Current Signature Analysis (MCSA): By analyzing the electrical signature of a motor, you can detect rotor bar issues, eccentricity, and other electrical or mechanical faults without installing sensors directly on the asset.
- Oil Analysis: Sensors can provide real-time analysis of particle count, viscosity, and water contamination in lubricating oils, giving deep insight into the health of gearboxes and hydraulic systems.
- Connectivity & The Edge: Data can be sent to the cloud via wired connections (e.g., Modbus, OPC-UA) or, more commonly, via wireless IIoT protocols like LoRaWAN, Wi-Fi, or Cellular (including 5G). Modern architectures often use a hybrid Edge-Cloud model. An edge device located near the asset performs initial data processing, filtering out noise and running simple anomaly detection algorithms. This reduces the volume of data sent to the cloud, saving bandwidth and enabling faster, localized alerts. The heavy-duty machine learning model training and long-term trend analysis then happen in the cloud.
The Heart of the Platform: AI and Machine Learning Models
This is the brain of the operation, where raw data is transformed into predictive insight.
- Supervised Learning: These models are trained on labeled historical data. For example, you feed the model sensor data from dozens of past bearing failures, along with the "label" that a failure occurred. The model then learns to recognize the patterns that precede a failure. This is used for calculating metrics like Remaining Useful Life (RUL).
- Unsupervised Learning: This is critical when you don't have extensive failure history (e.g., for a new asset). Unsupervised models, like autoencoders or clustering algorithms, learn the "normal" behavior of an asset. They then flag any deviation from that normal baseline as an anomaly, alerting you to a potential new or unknown failure mode.
- The Rise of Generative AI (GenAI) in Maintenance: Looking at 2025 and beyond, GenAI is a major trend. Instead of just analyzing numbers, it can process unstructured data. Imagine a system that reads decades of technician notes from your CMMS, correlates them with sensor data, and generates a diagnostic summary in plain English. It can also be used to automatically generate highly detailed, step-by-step PM procedures based on the specific predicted failure mode and the asset's manual.
- Model Explainability (XAI): A "black box" prediction is not enough. A technician won't trust an alert that just says "Failure Imminent." Explainable AI (XAI) is crucial. The platform must provide the "why" behind its prediction. For example: "Alert: High probability of pump failure. Reason: Increased vibration amplitude at 3x running speed, coupled with a 15°C rise in bearing temperature, is 92% correlated with advanced impeller wear based on historical data." This context is vital for trust and effective action. This is the core of true AI predictive maintenance.
The Integration & Action Layer: From Insight to Execution
Data and predictions are meaningless if they aren't integrated into your daily workflows.
- API-First Architecture: A modern PdM platform must be built with an Application Programming Interface (API) first. This ensures it can easily share data with and receive data from other enterprise systems like your ERP (e.g., SAP for parts ordering), EAM, and SCADA systems.
- The CMMS/EAM Connection: This is the most critical integration. The PdM platform is the "brain" that detects problems; the CMMS is the "body" that executes the work. The seamless flow of information—from predictive alert to automated work order to completed task and back—is what defines a successful, closed-loop system.
- Visualization & Dashboards: A good user interface presents complex data in an intuitive way. Key features include customizable dashboards with asset health scores, RUL countdowns, historical trend charts, and geographical maps showing the status of all your assets.
The Future is Here: What's Next for Cloud-Based Predictive Maintenance?
The technology is not standing still. The platforms of today are paving the way for even more powerful capabilities.
- Hyper-Personalized Maintenance: Models will become so refined they are trained not just for a "500hp pump," but for your specific 500hp pump, operating in your unique environment, processing your specific product.
- Federated Learning: To address data privacy concerns, this emerging technique allows the central AI model to be trained by sending the model to the data (at the edge or in a private cloud), rather than sending the raw data to a central cloud, enhancing security.
- Augmented Reality (AR) Integration: A technician wearing AR glasses will look at an asset and see a real-time overlay of its health data—temperature, vibration, RUL. The glasses could then display the prescriptive work order and guide them through the repair step-by-step.
Conclusion: Your Competitive Edge Awaits
Implementing a cloud-based predictive maintenance platform is no longer a futuristic luxury; it is an accessible and essential strategy for any industrial operation looking to thrive in a competitive landscape. By moving from a reactive, costly maintenance culture to a proactive, data-driven one, you unlock immense value: drastically reduced downtime, significantly lower maintenance costs, improved worker safety, and a powerful, sustainable competitive advantage.
The journey begins not with a massive, risky investment, but with a strategic, phased approach focused on your most critical assets. By proving the value at each step, you can build the momentum and the business case to transform your entire maintenance and reliability operation.
Ready to move from reactive firefighting to proactive, data-driven asset management? Explore how our Predictive Maintenance Platform can be the cornerstone of your Industry 4.0 strategy. Schedule a demo today to see it in action.
